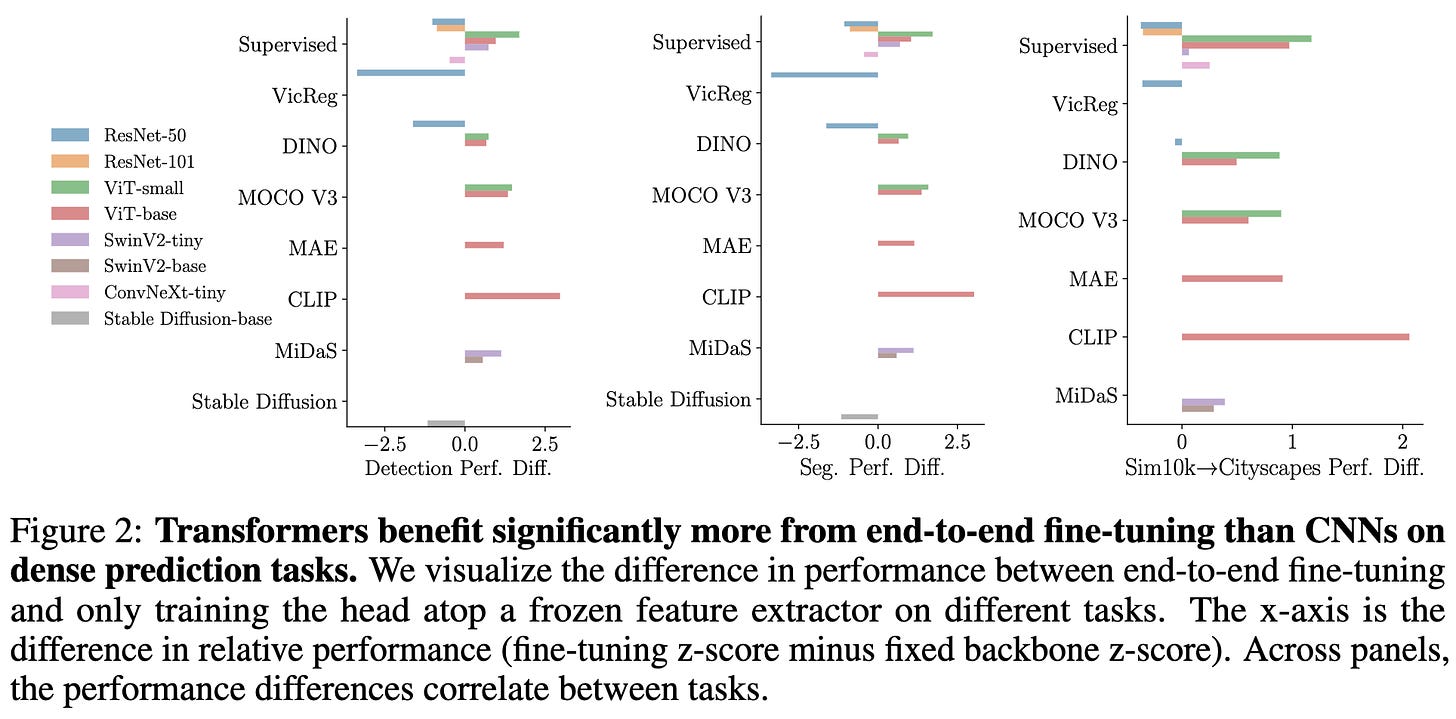
We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on
2023-11-19 arXiv roundup: Inverse-free inverse Hessians, Faster LLMs, Closed-form diffusion
PDF) Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives
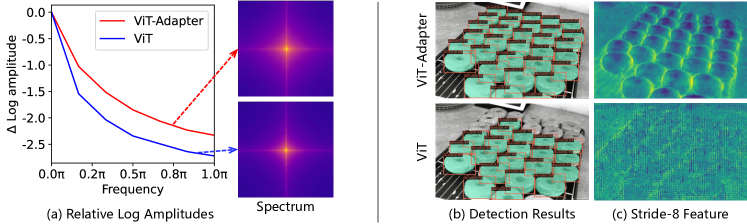
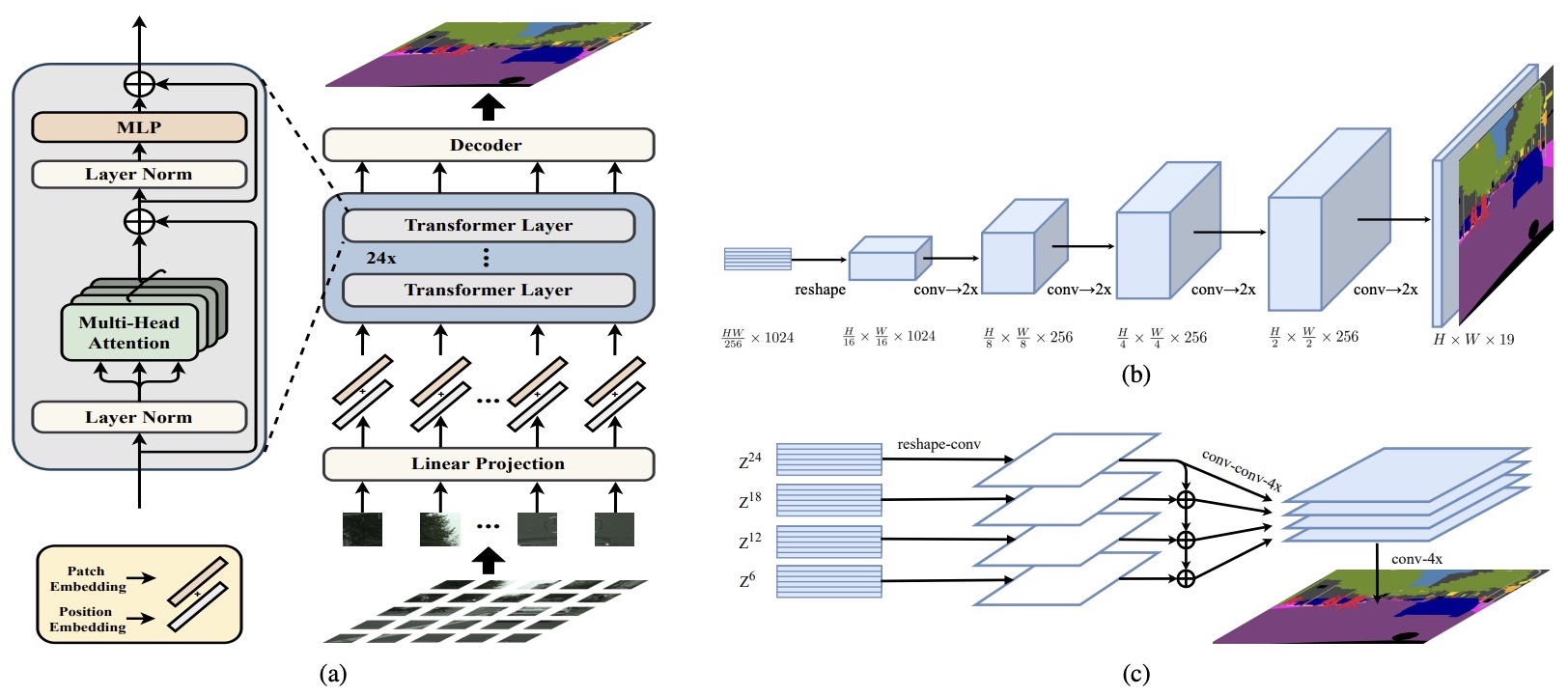
2205.08534] Vision Transformer Adapter for Dense Predictions

PDF) How to Fine-Tune Vision Models with SGD
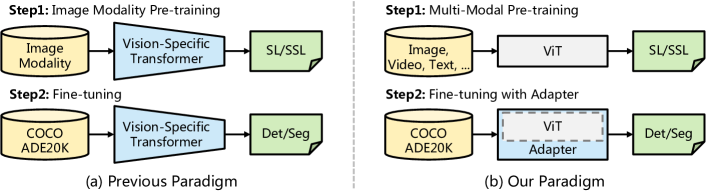
2205.08534] Vision Transformer Adapter for Dense Predictions

2301.02240] Skip-Attention: Improving Vision Transformers by Paying Less Attention

Remote Sensing, Free Full-Text

Ruoqi Shen's research works
We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on

D] Finetune pretrained ViT : r/MachineLearning
Aman's AI Journal • Papers List