Spark Performance Optimization Series: #1. Skew, by Himansu Sekhar, road to data engineering

In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Spark Performance Optimization Series: #3. Shuffle, by Himansu Sekhar, road to data engineering

Apache Spark Optimization Toolkit

Stream Data from Kinesis to Databricks with Pyspark, by Himansu Sekhar, road to data engineering
How Adobe Does Millions of Records per Second Using Apache Spark Optimizations — Part 2, by Jaemi Bremner

End-to-End Data Engineering System on Real Data with Kafka, Spark, Airflow, Postgres, and Docker, by Hamza Gharbi

Himansu Sekhar – Medium
Performance Optimization of Spark-SQL
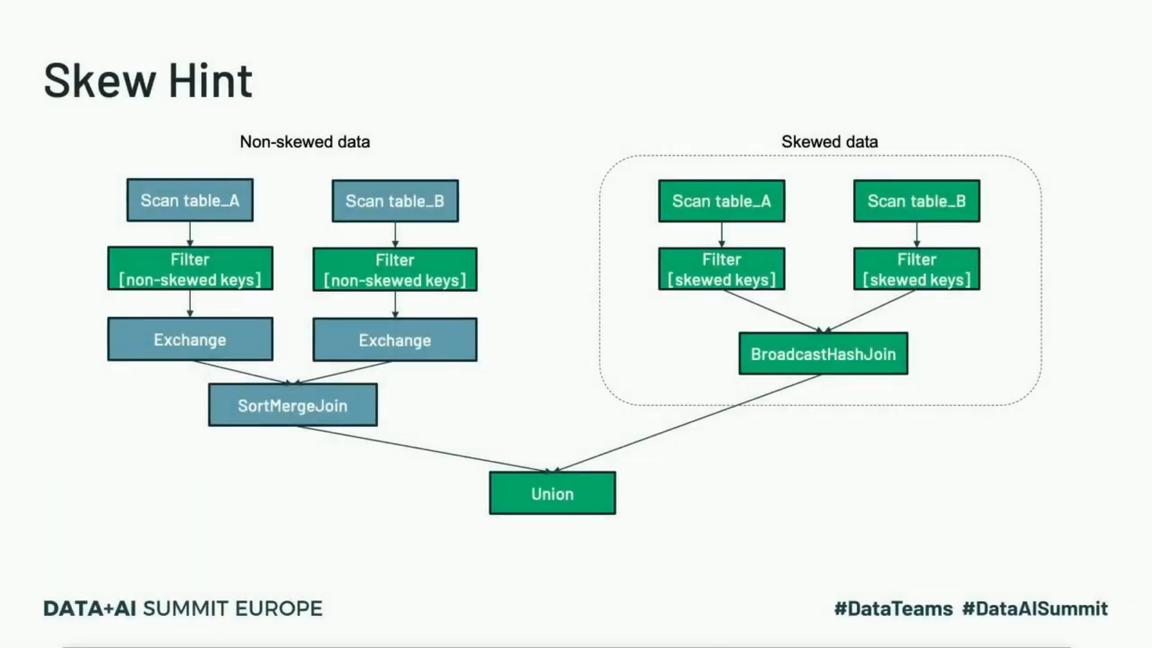
Performance optimization lessons from Spark+AI and Data+AI Summits on - articles about Apache Spark

New Optimization Technique in Spark 3.0

Apache Spark Core—Deep Dive—Proper Optimization Daniel Tomes Databricks

Spark Performance Tuning: Skewness Part 1, by Wasurat Soontronchai

Data engineering and intelligent computing : proceedings of IC3T 2016 978-981-10-3223-3, 9811032238, 978-981-10-3222-6