DeepSpeed: Accelerating large-scale model inference and training via system optimizations and compression - Microsoft Research
Last month, the DeepSpeed Team announced ZeRO-Infinity, a step forward in training models with tens of trillions of parameters. In addition to creating optimizations for scale, our team strives to introduce features that also improve speed, cost, and usability. As the DeepSpeed optimization library evolves, we are listening to the growing DeepSpeed community to learn […]
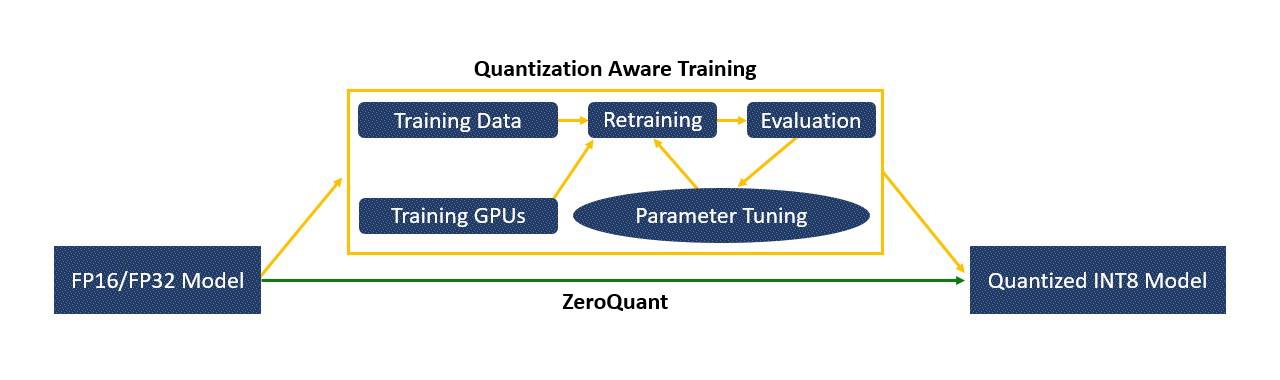
DeepSpeed Compression: A composable library for extreme compression and zero-cost quantization - Microsoft Research
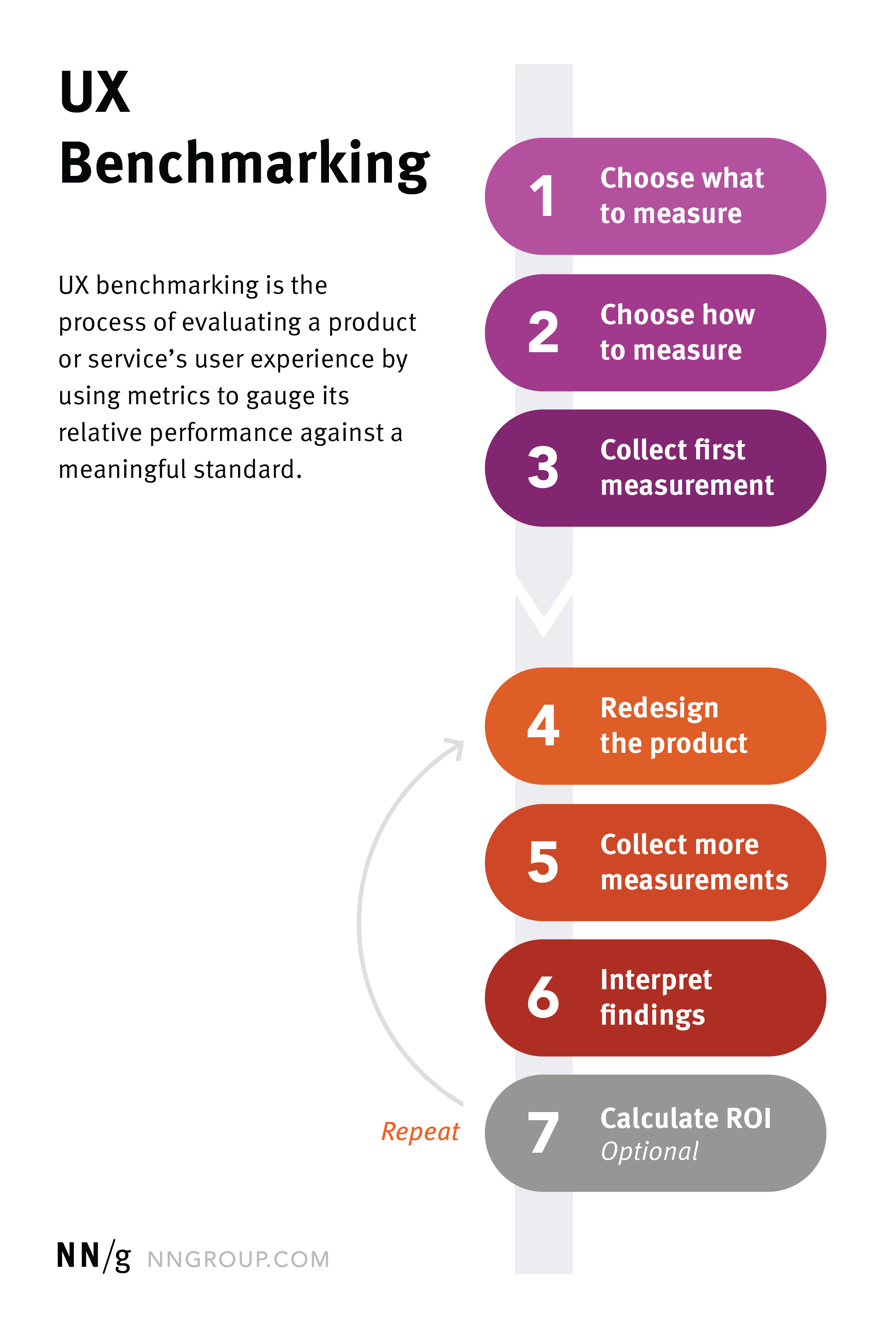
media.nngroup.com/media/editor/2020/07/31/ux-bench
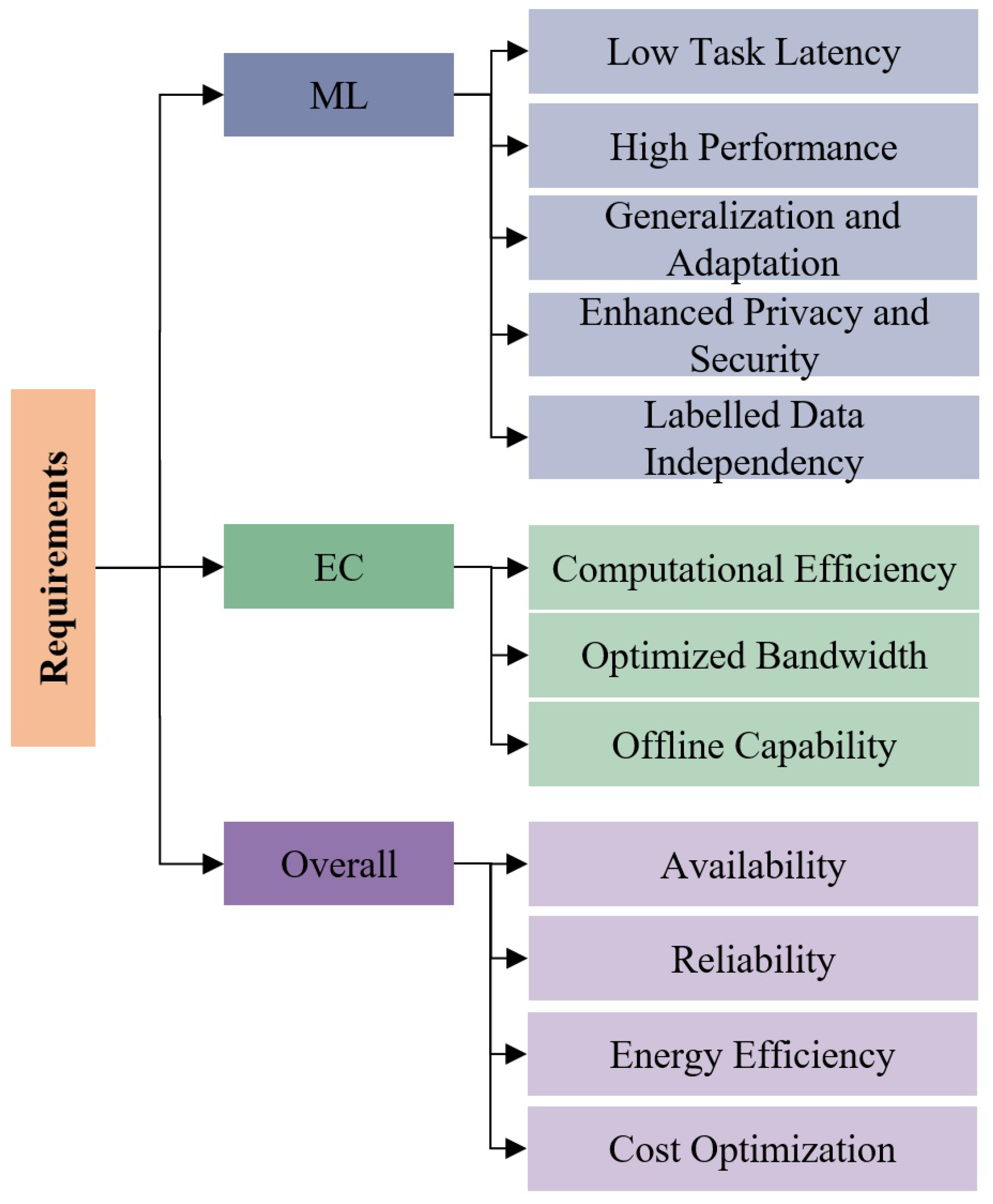
AI, Free Full-Text
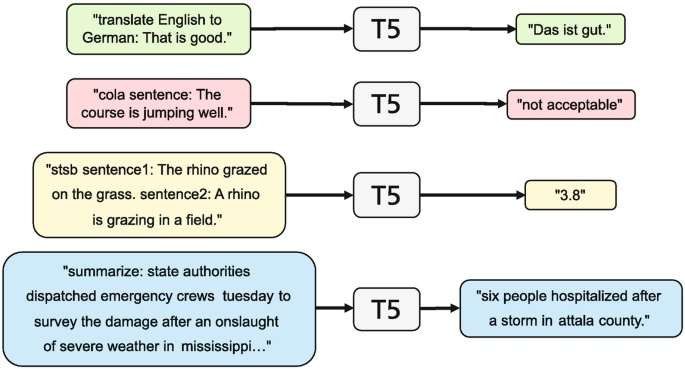
Improving Pre-trained Language Models
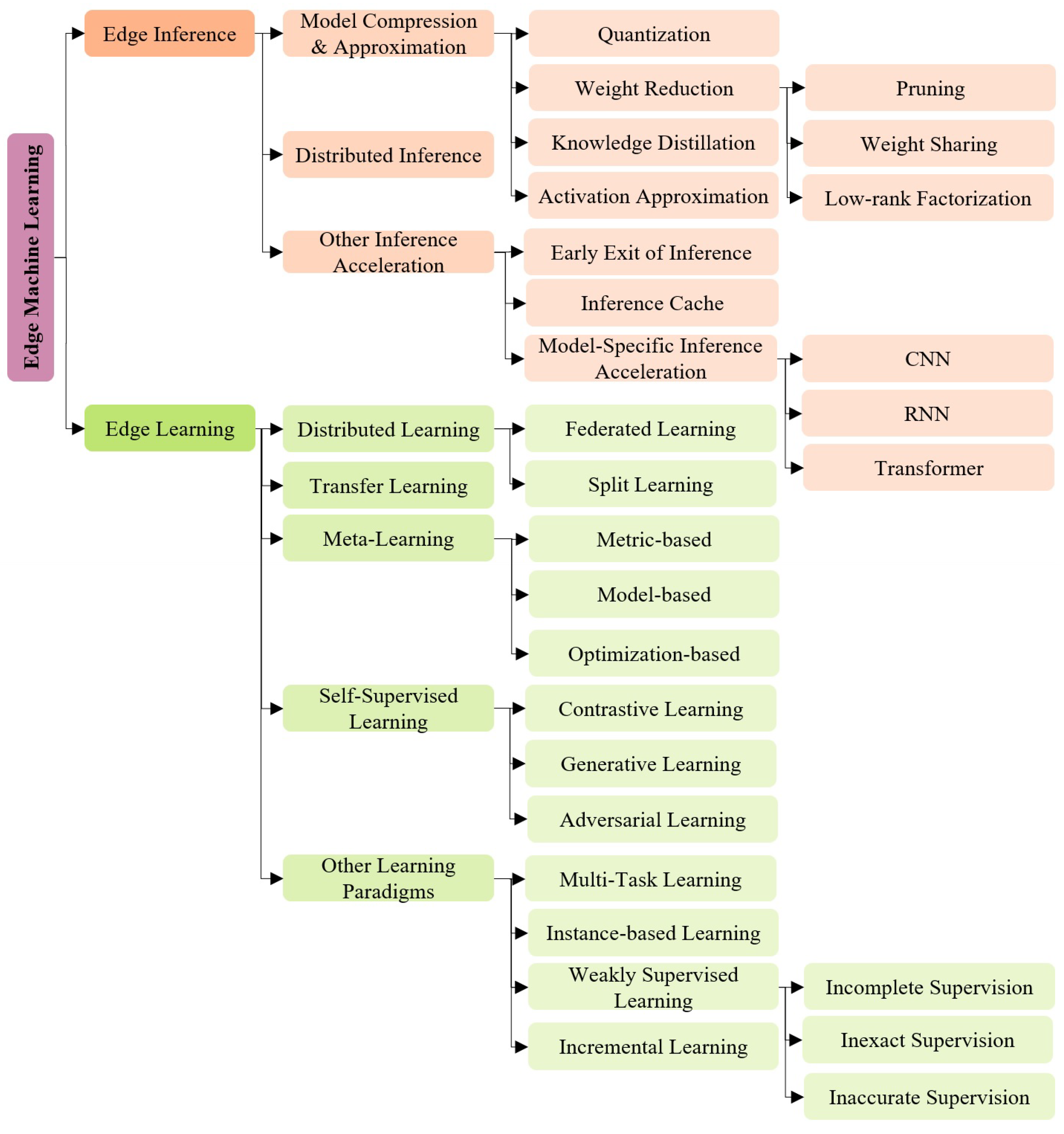
AI, Free Full-Text

the comparison of test and training time of benchmark network

Microsoft's DeepSpeed enables PyTorch to Train Models with 100-Billion-Parameter at mind-blowing speed, by Arun C Thomas, The Ultimate Engineer

DeepSpeed: Microsoft Research blog - Microsoft Research

Deploy BLOOM-176B and OPT-30B on SageMaker with large model inference Deep Learning Containers and DeepSpeed
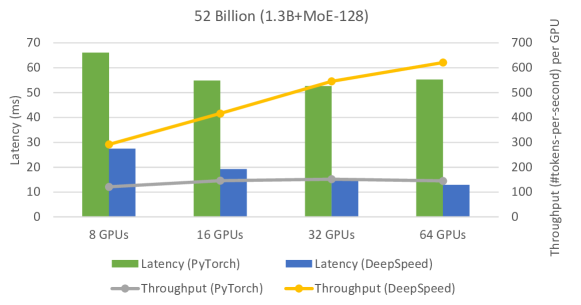
2201.05596] DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
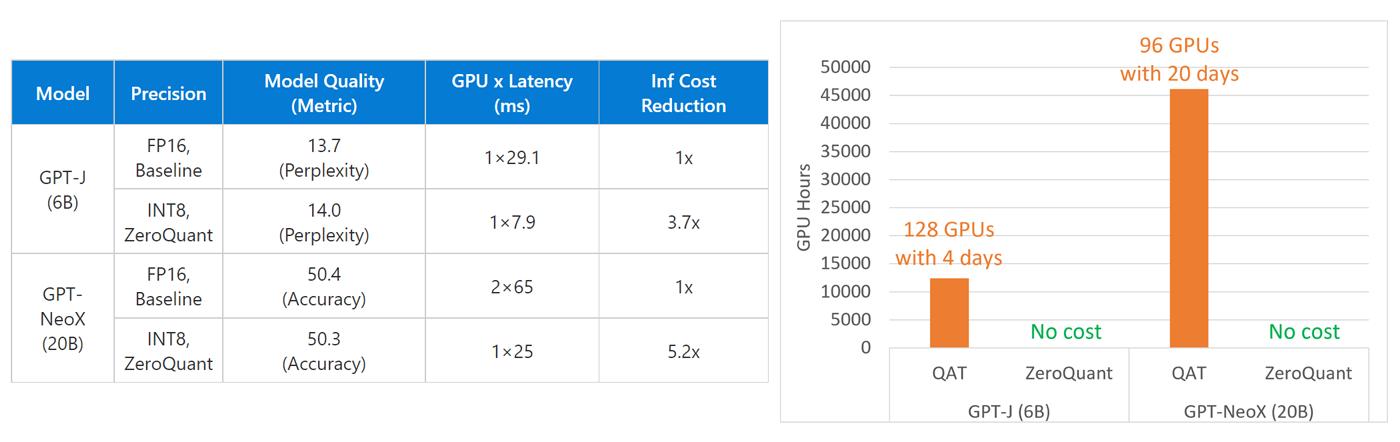
DeepSpeed Compression: A composable library for extreme compression and zero-cost quantization - Microsoft Research
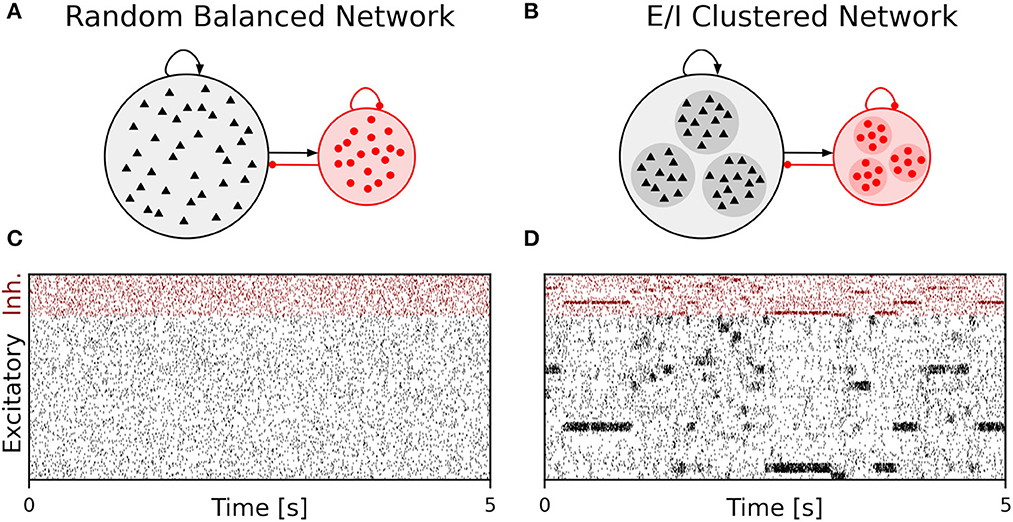
www.frontiersin.org/files/Articles/941696/fninf-17

DeepSpeed: Advancing MoE inference and training to power next-generation AI scale - Microsoft Research